L’Intelligenza Artificiale per la Pubblica Amministrazione – “La PA come compagnia petrolifera del dato”
Ora che il White Paper “L’Intelligenza Artificiale al servizio del cittadino” al quale ho avuto il piacere e l’onore di contribuire è stato pubblicato, mi permetto di condividere uno dei miei contributi a cui tengo particolarmente e che per giuste necessità di sintesi, traspare solo parzialmente nel documento pubblicato e consultabile a questo link: https://ia.italia.it/assets/librobianco.pdf
La sfida in oggetto è quella dei DATI, che è un patrimonio che vorrei vedere sfruttato maggiormente per produrre nuovi servizi e risorse per le PMI, il cittadino e chiunque voglia partecipare all’ecosistema.
– – – – – – –
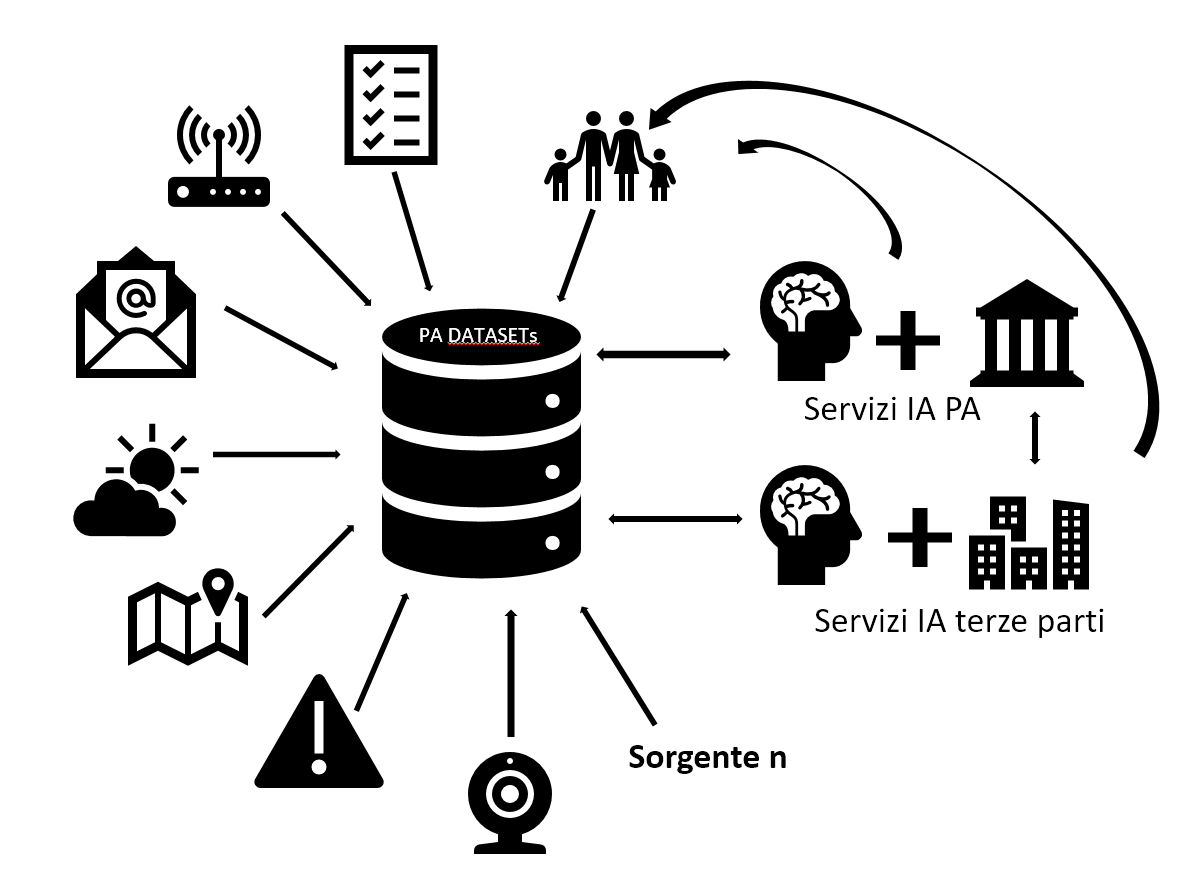
“La PA come compagnia petrolifera del dato” – I dati sono il petrolio dei giorni nostri e la PA siede su un giacimento parzialmente inesplorato ed inutilizzato che potrebbe generare un circolo virtuoso. Gli algoritmi di Machine Learning si basano e possono essere generati solo se si hanno a disposizione moli sufficienti di dati opportunamente organizzati e strutturati. Per dare un’idea, per effettuare il training di un modello efficiente in grado di riconoscere il parlato di una persona (Speech Recognition), Google ha utilizzato 50 Milioni di campioni come training set (Voice Samples)1. I dati a disposizione della PA possono provenire da fonti diverse come potrebbe essere un impianto elettrico, un sensore posizionato su un tombino, lo storico della manutenzione effettuata su una strada, il titolo o contenuto delle e-mail ricevute dai cittadini, un feed in tempo reale sulle previsioni meteo e così via. La PA ha l’opportunità di partecipare “all’economia del dato” oltre che generando servizi a valore aggiunto per il cittadino, anche creando un ecosistema che possa essere volano per le imprese del territorio interessate a generare servizi di Intelligenza Artificiale.
Alcuni dati, anche se in maniera minima e con un formato poco idoneo al Machine Learning sono ad oggi già a disposizione della PA (http://www.dati.gov.it/). Tuttavia, il processo d’immagazzinamento, organizzazione ed utilizzo necessita di una sostanziale revisione per poter diventare dataset utili allo sviluppo di servizi di Intelligenza Artificiale. Altri dati potrebbero essere invece derivati da quelli esistenti ed altri ancora potrebbero venire raccolti in base alle esigenze della PA e alle problematiche che si vogliono affrontare.
- Dati esistenti: Questi dati sono sparsi sul territorio e raccolti in formati diversi (inclusa l’archiviazione cartacea). Pensiamo a ciò che l’anagrafe ha a disposizione, alla mappatura degli impianti elettrici, alle informazioni provenienti dal catasto o a quelle ricavabili dalla manutenzione delle strade.
- Dati derivati: È possibile generare dati utili anche aggregando o eseguendo operazioni sui dati disponibili. In base al fine, si avranno una serie di elementi che possono generare un valore distribuibile per la PA
- Nuovi dati: Si tratta delle opportunità che l’IoT (Internet Of Things) ci offre. Pensiamo a sensori installabili sui margini dei corsi d’acqua, stream provenienti da videocamere, analytics provenienti dai siti web istituzionali consultati dai cittadini, dati acquisiti da terze parti e molto altro ancora
Tuttavia, ad oggi non esiste un sistema centralizzato adeguato per la raccolta\generazione e gestione del dato che permetterebbe di raggiungere la massa critica di informazioni necessarie per lo sviluppo (e l’ottimizzazione) di sistemi basati sul Machine Learning. Alcuni dei passi da esplorare sono quelli di:
- Centralizzare la raccolta del dato
- Consentire al cittadino di conoscere quali elementi vengono utilizzati e come
- Strutturare il formato del dato raccolto in base ai dataset che si vogliono generare
- Supervisionare il dato raccolto ed elaborato per evitare dataset sbilanciati (bias)
- Gestire l’accesso al dato
- Regolamentare l’utilizzo del dato
Nel pensare alla centralizzazione del dato, va ricordato che l’Italia si trova in una situazione di svantaggio rispetto ad altre nazioni in quella che è l’”Economia del dato”. È per questo che l’esigenza di accelerare la centralizzazione e la generazione di dati è uno degli elementi più pressanti da tenere in considerazione. Nazioni come Cina e Stati Uniti in primis dispongono di popolazioni più ampie e di conseguenza di possibilità di generare dataset maggiori. Lo stesso ragionamento si applica alla lingua parlata, dove sappiamo che l’Italiano è parlato da meno dell’1% della popolazione mondiale mentre la lingua cinese dal 14,1% e l’inglese dal 5,5% 2. Queste discrepanze possono creare gap quantitativi nella raccolta dei dati e qualitativi nello sviluppo di servizi di Intelligenza Artificiale.
Con opportuni investimenti, la PA può fornire un contributo concreto per rendere l’Italia un ecosistema competitivo sopperendo a carenze strutturali (vedasi popolazione e lingua), con processi avanzati atti alla generazione, raccolta ed utilizzo dei dati.
1 Fonte: Rishi Chandra – Vice President of Product Management and GM of Home Products Google
2 Lingue per numero di parlanti madrelingua
– – – – –
Il Libro Bianco pubblicato da AgID è solo l’inizio di un percorso e vuole essere uno stimolo per chi potrà e dovrà gestire l’integrazione e l’effetto che i servizi di AI avranno sul cittadino. La gestione dei dati è un’opportunità per la PA e per l’Italia, così come lo è la formazione del personale e dei lavoratori del futuro che avranno a che fare ogni giorno con i servizi di Intelligenza Artificiale.
Consiglio una lettura del testo integrale (una settantina di pagine, immagini incluse :)) e per chi volesse, è possibile partecipare alla discussione https://ia.italia.it/community/ e magari spingere affinché il governo realizzi l’opportunità dell’Ecosistema del dato 🙂